Random walk#
What you need to know
Summing independent random variables results in another random variable called sumple sum. The mean of the sample sum is different from the population mean or expectation which is an exact quantity we want to approximate by sampling.
The Law of Large Numbers is a principle that states that as the number \(N\), the sample mean approaches the population mean with a standard deviation falling off as \(N^{-1/2}\)
The Central Limit Theorem (CLT) tells us that summing independent and identically distributed random variables with well-defined means and variances results in Gaussian distribution regardless of the nature of a random variable.
A model of random walk describes the erratic, unpredictable motion of atoms and molecules, providing a fundamental model for diffusion processes and molecular motion in fluids. The number of steps to the right (or left) of a 1D random walker results in a binomial probability distribution. Following CLT binomial distribution in the large N limit can be shown to be well approximated by gaussian with the same mean and variance.
Sum of Random Variables#
Consider a sequence of independent and identically distributed (i.i.d.) random variables, \(X_1, X_2, \ldots\). Examples include coin tosses, the random displacement of a molecule, or the random placement of a molecule in the left vs. right corner of a box. Being identically distributed means each term has a well-defined mean \(\mu\) and variance \(\sigma^2\):
The sum of \(n\) random variables, denoted by \(S_n\), is called a sample sum, and average of sum is called a sample mean. Our goal is to understand how these summed or aggregated quantities behave as a function of sample size.
Expectation is always a linear operator. Variance in general is not. But for i.i.d. random variables, variance becomes linear operator. To show this we denote mean subtracted random variable as \(Y_i = X_i - \mu\) which has zero expectation \(E[Y_i] = 0\)
Because of the independence of random variables all cross-terms are zero \(E[Y_i Y_j] = 0\) for \(i \neq j\) and all the self-terms \(i=j\) are equal to variance \(E[Y^2_i] = V[X_1]=\sigma^2\)
Law of Large Numbers (LLN)#
Both mean and variance of sum of random variables grows linearly with \(n\):
This has consequence on how we estimate means from samples \(M_n = \frac{1}{n} S_n\).
Sample mean becomes increasingly more accurate with the error or standard deviation decaying with \(1/2\) exponent.
Simulate tests of LLN#
import numpy as np
import ipywidgets as widgets
from ipywidgets import interact, interactive
import matplotlib.pyplot as plt
for N in [10, 100, 1000, 10000]:
M = np.random.randint(1, 10, N)/N
print(M.var()) #sample variance decays
0.0404
0.00051
7.1458039999999995e-06
6.7033e-08
# Number of trials and runs
N, runs = int(1e5), 30
# Store fractions of heads for each trial in each run
fractions = np.zeros((runs, N))
# Simulate coin tosses
for run in range(runs):
# Generate coin tosses (0 for tails, 1 for heads)
tosses = np.random.randint(2, size=N)
# Calculate cumulative sum to get the number of heads up to each trial
cum_heads = np.cumsum(tosses)
# Calculate fraction of heads up to each trial
fractions[run, :] = cum_heads / np.arange(1, N+1)
# Plotting
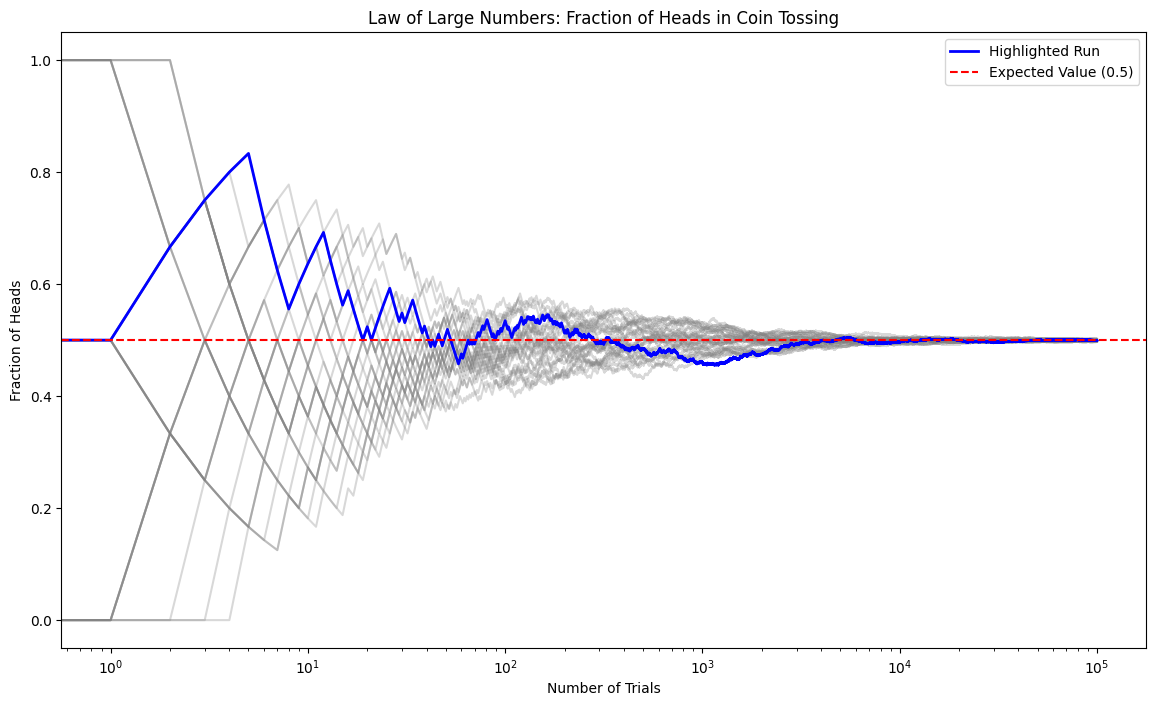
plt.figure(figsize=(14, 8))
# Plot all runs with low opacity
for run in range(runs):
plt.plot(fractions[run, :], color='grey', alpha=0.3)
# Highlight first run
plt.semilogx(fractions[0, :], color='blue', linewidth=2, label='Highlighted Run')
# Expected value line
plt.axhline(y=0.5, color='red', linestyle='--', label='Expected Value (0.5)')
plt.xlabel('Number of Trials')
plt.ylabel('Fraction of Heads')
plt.title('Law of Large Numbers: Fraction of Heads in Coin Tossing')
plt.legend()
<matplotlib.legend.Legend at 0x165390580>
The Central Limit Theorem (CLT)#
Central Limit Theorem asserts that the probability distribution function or PDF of sum of random variables becomes gaussian distribution with mean \(n\mu\) and \(n\sigma^2\). Note that CLT is based on assumption that the mean and variance, \(\mu\) and \(\sigma^2\), are finite!. Thus, CLT does not hold for certain power-law distributed RVs.
If we subtract mean and scale the sample sum by its standard deviation we will get a standard normal distribution $.
Simulate CLT#
from scipy.stats import norm
# Number of coin tosses in each experiment, number of experiments
N, runs = 100, 1000
# Simulate coin tosses: num_experiments rows, num_tosses_per_experiment columns
tosses = np.random.randint(2, size=(N, runs))
# Calculate means of each experiment
M = np.mean(tosses, axis=0)
z = ( M-M.mean() ) / np.std(M)
# Plotting the distribution of sample means
plt.figure()
plt.hist(z, density=True, bins=30)
plt.title('Distribution of Sample Means of Coin Tosses')
plt.xlabel('Sample Mean')
plt.ylabel('Density')
zs = np.linspace(z.min(), z.max(), 1000)
plt.plot(zs, norm.pdf(zs),'k', label='mean=0, var=1')
plt.legend()
Random walk#
Tossing a coin a few times generates a random sequence of outcomes e.g HTHTTT
Probability of landing H vs T for a fair coin is \(\theta=1/2\). Therefore the probability of any \(n\) long sequence is always equal \(\theta^N=2^{-N}\). A more interesting question is finding probability of having \(n\) heads out of N tosses. For a fair coin this is same question as finding number of combination of n heads out of N tosses:
More generally the probability to generate \(n\) heads after N coin tosses with a coin that has a bias \(\theta\) is given by:
Another popular application of 1D random walk is to understand diffusive phenomena. A molecule which starts at 0 and which moves via consecutive jumps in left vs right direction with probabilities \(\theta\) and \(1-\theta\) will make \(n\) jumps to the right out of N jumps with \(p(n|N, \theta)\) probability. An interesting question for diffusion is to compute average displacement of molecule relative to origin. We can rewrite probability in terms of net displacement \(x = n - (N-n)\) or \(n = \frac{x+N}{2}\)
Law of large numbers and random walk#
Applying the formulas to random walk model we get mean and variance for single step
Since steps of a random walker are independent we can compute the variance of a total displacement by multiplying mean and varaince of a single step by N
The variance of the mean \(\bar{x} = x/N\) would then be:
Simulating a 1D unbiased random walk#
Each random walker will be modeled by a random variable \(X_i\), assuming +1 or -1 values at every step. We will run N random walkers (rows) over n steps (columns)
We then take cumulative sum over n steps thereby summing n random variables for N walkers. This will be done via a convenient
np.cumsum()method.
def rw_1d(n, N):
'''
n: Number of steps
N: Number of walkers
returns np.array with shape (n, N)
'''
# Create random walks
r = np.random.choice([-1,1], size=(n, N))
#Sum over n steps
rw = r.cumsum(axis=0)
#Set initial position
rw[0,:]=0
return rw
rw = rw_1d(2000, 1000)
print(rw.shape)
(2000, 1000)
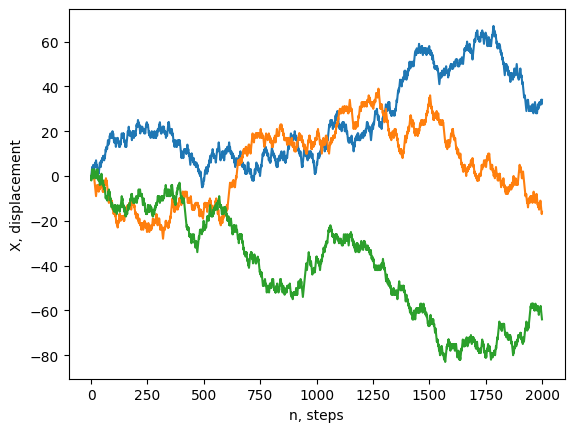
plt.plot(rw[:,:3]) # plot a few random walkers
plt.ylabel('X, displacement')
plt.xlabel('n, steps')
Text(0.5, 0, 'n, steps')
from scipy import stats
# Simulate 1D random walk
n_max = 1000
N = 1000
rw = rw_1d(n_max, N)
def rw_plotter(t=1):
fig, ax = plt.subplots(nrows=2)
### plot random walk
ax[0].plot(rw)
ax[0].axvline(x=t, color='black', linestyle='-', lw=2)
## Plot gaussian with width t**0.5
ax[1].hist(rw[t, :],
color='orange',
density=True,
label=f'time={t}')
x = np.linspace(rw.min(), rw.max(), 1000)
y = stats.norm.pdf(x, 0, np.sqrt(t))
ax[1].plot(x, y,
color='black',
lw=2,
label='normal')
ax[0].set_xlabel('X')
ax[0].set_ylabel('t')
ax[0].set_title('RW trajectries');
ax[1].set_xlabel('X')
ax[1].set_ylabel('p(x)')
ax[1].set_xlim([-100, 100])
ax[1].legend()
ax[1].set_title('$\sigma/t$='+f'{np.var(rw[t, :])/t:.3f}')
fig.tight_layout()
plt.show()
interactive( rw_plotter, t=(1, n_max-1) )
Question
Would sample mean get more accurate or less as a function of time?
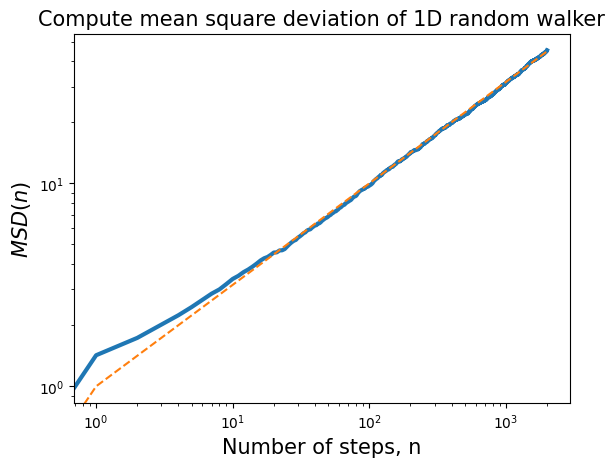
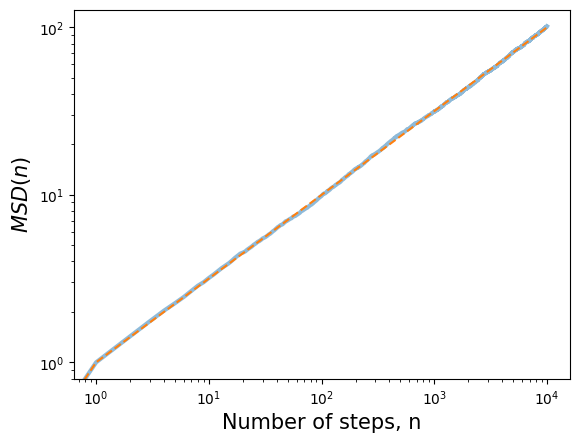
Mean square displacement (MSD) of a random walker#
After time n number of steps (or time t) how far has random walker moved from the origin?
We quantify this by computing Mean Square Displacement (MSD). Note that the mean is computed over N number of simulated trajectories (ensemble average). Invoking central limit theorem, or simply realizing that off diagonal terms drop off we end up with the same result as in LLN.
n, N = 2000, 1000
rw = rw_1d(n, N)
t = np.arange(n)
R2 = (rw[:, :] - rw[0, :])**2 # Notice we subtract initial time
msd = np.mean(R2, axis=1) # Notice we average over N
plt.loglog(t, np.sqrt(msd), lw=3)
plt.loglog(t, np.sqrt(t), '--')
plt.title('Compute mean square deviation of 1D random walker',fontsize=15)
plt.xlabel('Number of steps, n',fontsize=15)
plt.ylabel(r'$MSD(n)$',fontsize=15);
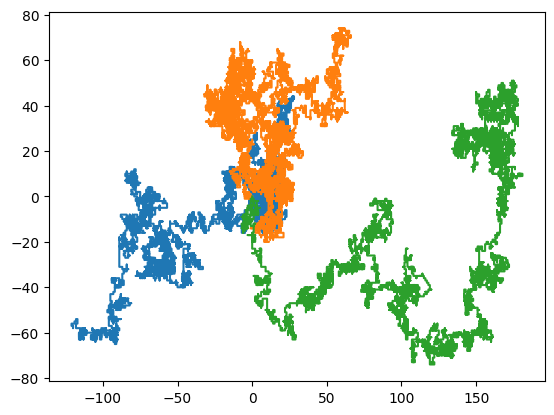
2D random walk#
def rw_2d(n, N):
'''2d random walk function:
n: Number of steps
N: Number of trajecotry
returns np.array with shape (T, N)
'''
verteces = np.array([(1, 0),
(0, 1),
(-1, 0),
(0, -1)])
rw = verteces[np.random.choice([0,1,2,3], size=(n, N))]
rw[0, :, :] = 0
return rw.cumsum(axis=0)
traj = rw_2d(n=10000, N=1000)
traj.shape
(10000, 1000, 2)
plt.plot(traj[:,:3, 0], traj[:,:3, 1]) # plot first three random walkers
[<matplotlib.lines.Line2D at 0x168d9fca0>,
<matplotlib.lines.Line2D at 0x168d9fc70>,
<matplotlib.lines.Line2D at 0x168d9fd90>]
Compute RSD for 2D random walker#
#Simulate 2D random walk
n, N = 10000, 1000
traj = rw_2d(n, N)
#Compute RSD
dx = (traj[:, :, 0]- traj[0, :, 0])
dy = (traj[:, :, 1]- traj[0, :, 1])
R2 = np.mean(dx**2 + dy**2, axis = 1) # notice that we are averaging over N walkers
R2.shape
(10000,)
fig, ax = plt.subplots()
t = np.arange(n) # time axis
ax.loglog(t, np.sqrt(R2), lw=3, alpha=0.5);
ax.loglog(t, np.sqrt(t), '--');
ax.set_xlabel('Number of steps, n',fontsize=15)
ax.set_ylabel(r'$MSD(n)$',fontsize=15);
Appendix A: Stitrling’s approximation of N!
Stirling’s approximation
This is the crude version of Stirling approximation that works out for \(N\gg 1\)
A more accurate version is:
Applying Stirling approximation to the Binomial
The expression \(S = \sum_i -p_i log p_i\) will be identified with Entropy in later sections.
Appendix B. Gaussian approximation to the Binomial Distribution in the large \(N\) limit.
Binomial distribution for large values of \(N\) has a sharply peaked distribution around its maximum (most likely) value \(\bar{n}\). This motivates us to seek a continuous approximation by Taylor expanding probability distribution around its max value \(\Delta n = n-\bar{n}\) and keeping up to quadratic terms.
Thus from the onset we are aiming for a Gaussian distribution. The task then is to find coefficients and to then justify that third term of Taylor expansion is negligible compared to the second!
We evaluate derivative of \(logn!\) in the limit of \(n\gg1\) as:
We could also arrive at the same result by using Stirling approximation \(logN! \approx NlogN -n\)
Taking first derivative of Taylor expansion to Binomial we find the peak of the distribution around which we are making expansion:
We recall that \(\bar{n} = Np\) is also mean of the binomial!
Having found the peak of distribution and knowing first derivative we now proceed to compute the second derivative:
While first derivative gave us the mean of binomial we notice that second derivative produces the variance \(\sigma^2 = Npq\)
Now all that remains to do is to plug the coefficients into our approximated probability distribution and then normalize it. Why normalize? After all Binomial was already properly normalized. But since we made approximation by leaving our some terms we have to re-normalize again!
Normalizing gaussian distribution is done via the following table integral
At last we have the normalized approximation to Binomial which is a guassian distribution arond mean!
Appendix C. Deriving Poisson distribution from Binomial
Consider the limit of large \(N\) and small \(p\) such that \(Np=const\)
This is a situation of rare events like rains in forest or radioactive decay of uranium where each individual event has small chance of happening \(p \rightarrow 0\) yet there are large number of samples \(N\rightarrow \infty\) such that one has a constant average rate of events \(\lambda = pN = const\)
In this limit distirbution is no longer well described by the gaussian as the shape of distribution is heavily skewed due to tiny values of p.
Writing factorial \(N!/(N-n)!\) explicitely we realize that it is dominated \(N^n\) and also \(N-n \approx N\)
Next let us plug in \(\lambda = pN = const\) and recall the definition of exponential \(lim_{x\rightarrow \infty }(1-1/x)^x = e^{-x}\)
Problems#
Confined diffusion.#
Simulate 2D random walk in a circular confinement. Re-write 2D random walk code to simulate diffusion of a particle which is stuck inside a sphere. Study how root mean square deviation of position scales with time.
Carry out simulations for different confinement sizes.
Make plots of simulated trajectories.
Return to the origin!#
Simulate random walk in 1D and 2D for a different number of steps \(N=10, 10^2,10^3, 10^4, 10^5\)
Compute average number of returns to the origin \(\langle n_{orig} \rangle\). That is number of times a random walker returns to the origin \(0\) for 1D or (0,0)$ for 2D . You may want to use some 1000 trajectories to obtain average.
Plot how \(\langle n_{orig} \rangle\) depends on number of steps N for 1D and 2D walker.
Breaking the CLT; Cauchy vs Normal random walk in 2D#
For this problem we are going to simulate two kinds of random walks in continuum space (not lattice): Levy flights and Normal distributd random walk.
To simulate a 2D continuum space random walk we need to generate random step sizes \(r_x\), \(r_y\). Also you will need unifrom random namber to sample angles in 2D giving you a conitnuum random walk in 2D space: \(x = r_x sin\theta\) and \(y=r_ycos\theta\)
Normally: \(r\sim N(0,1)\)
Cauchy distribution (long tails, infinite variance) \(r\sim Cauchy(0,1)\)
Unform angles \(\theta \sim U(0,1)\)
Visualize random walk using matplotlib and study statistics of random walkers the way that is done for normal random walk/brownian motion examples!
(Optional Problem) Continuous time random walk (CTRW)#
Simulate 1D random walk but instead of picking times at regular intervals pick them from exponential distribution.
Hint: you may want to use random variables from scipy.stats.exp
Study the root mean square deviation as a function of exponential decay parameter \(\lambda\) of exponential distribution \(e^{-\lambda x}\).
References#
The mighty little books
More in depth
On the applied side