Entropy#
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import widgets
Fig. 2 Introducing entropy#
Large deviation theory, entropy and free energy.#
Consider a 1D random walk again. Let us write down probability of a random walk taking \(n\) steps to right and \(n_2\) steps to left given that the probabilities are \(\theta\) probability to move to right and \(\theta_2\) to move to left respectively. By definition \(N=n_1+n_2\) and \(\theta_1+\theta_2=1\). Probability distribution of this random walk could represent polymer conformations or diffusing molecules.
We already know that in the limit of large N the distribution of sum of random variables becomes gaussian. But before N becomes too large and probability distribution converges to gaussian there is an intermediate regime where fluctuations are dominant and where a non-gaussian function controls the shape of the distribution. To see this we take the log and using Stirling approximation \(log N! = NlogN-N\) and using \(n=n_1\) and \(p=p_1\) as independent variables we get:
We find that probability to deviate from mean values decays exponentially with a decay function specific to a system and independent of N. The \(I\) a free energy per particle. Mathematicians call it large deviation function.
The expression involving fractions or observable probabilities of steps of moving to right and left; \(p_1=n_1/N\) and \(p_2=n_2/N\) is called Entropy.
The terms involving bias of a random walk \(\theta\) can be identified with Energy since it has the effect of tilting the random towards left or right.
@widgets.interact(theta=(0.01,0.99), N=(1,1000))
def large_dev(theta, N):
fmin, fmax, step=0, 1, 0.01
f = np.arange(fmin+step, fmax-step, step)
I = - f * np.log(theta) - (1-f)*np.log(1-theta) + f * np.log(f) + (1-f)*np.log(1-f)
plt.plot(f, I, linewidth=2.5, label=r'$I(p, \theta)$')
plt.plot(f, np.exp(-N*I), label=r'$e^{-NI(p, \theta)}$' )
plt.xlabel(r'$p$')
plt.ylabel(r'$I(p)$')
plt.legend()
plt.show()
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import comb
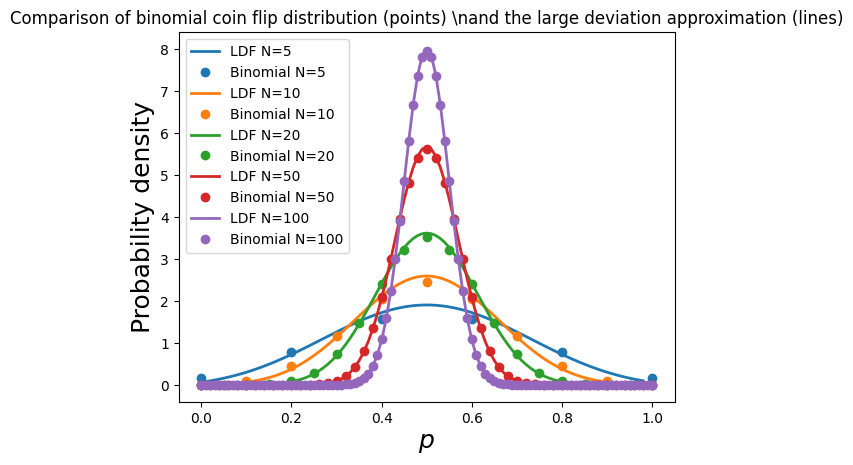
def plot_large_deviation(N, theta, color):
fmin, fmax, step=0, 1, 0.01
f = np.arange(fmin+step, fmax-step, step)
I = -f * np.log(theta) - (1-f)*np.log(1-theta) + f * np.log(f) + (1-f)*np.log(1-f)
p_ldt = np.exp(-N * I) / (np.sum(np.exp(-N * I))*step) # normalized probability
plt.plot(f, p_ldt, color=colors[i], label=f'LDF N={N}', linewidth=2)
def plot_binomial(N, theta, color):
n = np.arange(N+1)
f = n / N
prob = comb(N, n) * theta**n * (1-theta)**(N-n)
plt.plot(f, prob * N, 'o', color=color, label=f'Binomial N={N}')
# Parameters
theta = 0.5
Ns = [5, 10, 20, 50, 100]
# Use default colors from the current color cycle
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
for i, N in enumerate(Ns):
plot_large_deviation(N, theta, colors[i])
plot_binomial(N, theta, colors[i])
plt.xlabel(r'$p$', fontsize=18)
plt.ylabel(r'Probability density', fontsize=18)
plt.title(r'Comparison of binomial coin flip distribution (points) \nand the large deviation approximation (lines)', fontsize=12)
plt.legend(loc="upper left")
plt.show()
def comp_entropy(px, dx=1):
p = px*dx # np.sum(p)=1
return np.sum(-p*np.log2(p))
fair_die = 1/6*np.ones(6)
unfair_die = 1/6*np.array([5.5, 0.1, 0.1, 0.1, 0.1, 0.1])
comp_entropy(fair_die), comp_entropy(unfair_die)
(2.584962500721156, 0.6073108582109139)
np.sum(1/6*np.ones(1))
0.16666666666666666
dp = 1e-6 # to avoid taking log of zero
p_heads = np.linspace(dp, 1-dp, 1000)
# Calculate entropy for each probability
entropy_coin = -p_heads * np.log2(p_heads) - (1 - p_heads) * np.log2(1 - p_heads)
# Plot entropy as a function of the bias of the coin
plt.figure(figsize=(10, 6))
plt.plot(p_heads, entropy_coin, color='darkorange', label='Entropy')
plt.xlabel('Probability of Heads (Bias)')
plt.ylabel('Entropy (bits)')
plt.title('Entropy as a Function of Coin Bias')
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.legend()
plt.show()
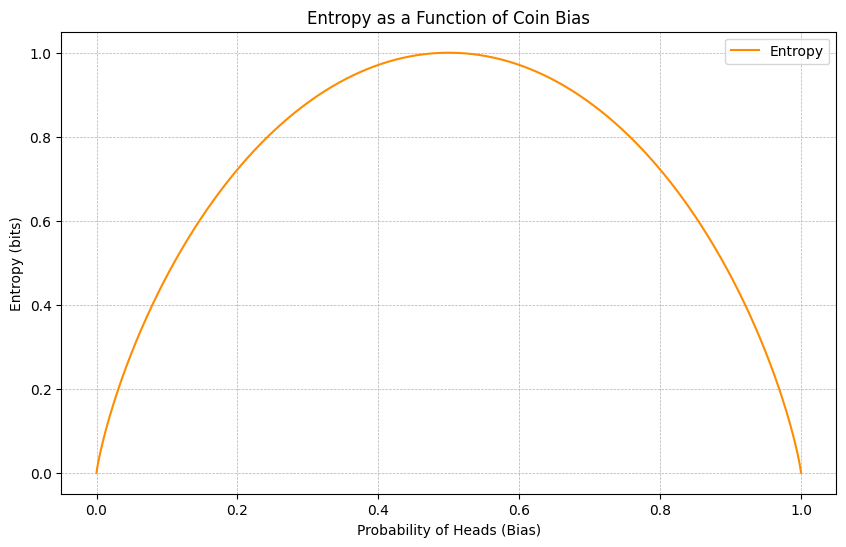
If you flip N fair coins which configuration (number of heads n out of N) will correspond to maximum entropy?
How much information is needed to find out how these coins landed?
def gauss(x, sigma):
return 1/np.sqrt(2*np.pi*sigma**2) * np.exp(-x**2/(2*sigma**2) )
def ent_g(sigma):
return 0.5 * np.log2(2 * np.pi * np.e * sigma**2)
def viz_gauss_entropy(sigma=1):
fig, (ax1, ax2) = plt.subplots(ncols=2)
x = np.arange(-100, 100, 0.01)
px = gauss(x, sigma)
ax1.plot(x, px, label=f'Entropy={ent_g(sigma):.3f}')
ax1.legend()
ax1.set_xlabel('x')
ax1.set_ylabel('p(x)')
ax1.set_ylim(0, 0.5)
#
sigmas = np.arange(20)
ax2.plot(sigmas, ent_g(sigmas), color='orange')
ax2.plot(sigma, ent_g(sigma), 'o', ms=10, color='red')
plt.show()
widgets.interact(viz_gauss_entropy, sigma=(1, 20))
<function __main__.viz_gauss_entropy(sigma=1)>
Entropy and Information#
Which of these two statements conveys the most information?
I will eat some food tomorrow.
I will see a giraffe walking by my apartment.
A measure of information (whatever it may be) is closely related to the element of… surprise!
has very high probability and so conveys little information,
has very low probability and so conveys much information.
If we quanitfy suprise we will quantify information
Knowledge leads to gaining information
Which is more surprising (contains more information)?
E1: The card is heart?
E2:The card is Queen?
E3: The card is Queen of hearts?
\(P(E_1) = \frac{1}{4}\)
\(P(E_2) = \frac{4}{52} = \frac{1}{13}\)
\(P(E_1 \, and\, E_2) = \frac{1}{52}\)
We learn the card is heart \(I(E_1)\)
We learn the card is Queen \(I(E_2)\)
\(I(E_1 and E_2) = I(E_1) + I(E_2)\)
Knowledge of event can add to information: \(I(E) \geq 0\)
A logarithm of probability is a good candidate function for information!#
Because information should be additive!
Why bit (base two)#
Consider symmetric a 1D random walk with equal jump probabilities. We can view Random walk = string of Yes/No questions.
Imagine driving to a location how many left/right turn informations you need to reach destination?
You gain one bit of information when you are told Yes/No answer
To decode N step random walk trajectory we need N bits.
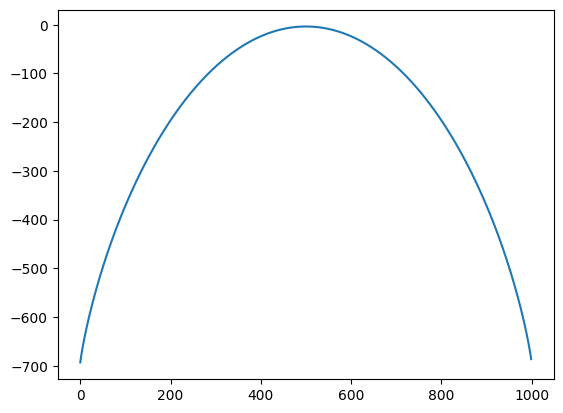
from scipy.stats import binom
N = 1000 #trials
p = 0.5 # probability of step to right
W_bin = [binom.pmf(n, N, p=p) for n in range(N)]
plt.plot( np.arange(N), np.log(W_bin) )
[<matplotlib.lines.Line2D at 0x180a27c10>]
Shannon Measure of Information (SMI)#
Surprise
Information is an average of surprise.!!! How surprised are you on average?
How many yes or no answers we need to reconstruct random walk.
How many yes/no answers to pinpoint weather molecules are in the left vs right side of container
How many yes/no answers to pinpoint precise conformation of a polymer
[To Shanon], You should call it Entropy, for two reasons. In the first place you uncertainty function has been used in statistical mechanics under that name. In the second place, and more importantly, no one knows what entropy really is, so in a debate you will always have the advantage.” J von Neumann
Information per letter \(I(m)\) to decode the message
\(m:\) Letters in the alphabet (Russian: 33,Enlgish: 26, Korean: 24)
\(I(Russian) > I(English) > I(Korean)\)
\(I(m_1, m_2) = I(m_1) + I(m_2)\) reagrdless of the order letters are sent!
One bit is an amount of information one can obtain from the answer to a single yes–no question. The number of bits to decode a message grows with the length of an alphabet and length of the word.
Alphabets are not random! hghjxcjxcc#
Some letters happen more often than the others! Probability of each letter in an independent sequence is \(p_m = \frac{1}{m}\)
We must send a message explaining how to combine the transferred symbols as a part of the message, but the length of the needed message is finite and independent of the length of the actual message we wish to send, so in the long message limit we may ignore this overhead.
Quantifying information#
How much knowledge we need to find out outcome of fair dice?
We are told die shows a digit higher than 2 (3, 4, 5 or 6). How much knowledge does this information carry?
\(H(E_1) = log_2 6\)
\(H(E_1) - H(E_2) = log_2 6 - log_2 4\)
Information per Letter of English#
If the symbols of English alphabet (+ blank) appear equally probably, what is the information carried by a single symbol? This must be \(log_2(26 + 1) = 4.755\) bits, but for actual English sentences, it is known to be about \(1.3\) bits. Why?
Two kittens#
There are two kittens. We are told that at least one of them is a male. What is the information we get from this message?
Game of message decoding:#
Given some 70 letters decode a 250 letter paragraph!
Cover T. M. and King, R. C. (1978). “A convergent gambling estimate of the entropy of English” IEEE Trans. Info. Theory, 24, 413–421
Monty Hall problem#
There are five boxes, of which one contains a prize. A game participant is asked to choose one box. After they choose one of the five boxes, the “coordinator” of the game identifies as empty three of the four unchosen boxes. What is the information of this message?
\(H(E_1) = log_2 5 = 2.322\)
\(H(E_2) = -\frac{1}{5} log_2 5 - \frac{4}{5} log_2 \frac{4}{5} = 0.722\)
\(H(E_1)-H(E_2) = 1.6\)
Non integer number of YES/NO questions??#
We have encountered a fraction of bit of information several times now. What does it imply in terms of number of YES/NO questions. That is becasue in some cases single YES/NO question can rule out more than one elementary event.
999 blue balls and 1 red ball. how many questions we need to ask to determin the colors of all balls? \(S = 9.97\) bit or 0.01 bit per ball. Divide the container by 500 and 500 and ask where the red ball is? 1 questions rules out 500 balls at once.
Is information physical?#
Wheeler’s It from bit.
Every it — every particle, every field of force, even the space-time continuum itself — derives its function, its meaning, its very existence entirely — even if in some contexts indirectly — from the apparatus-elicited answers to yes-or-no questions, binary choices, bits. It from bit symbolizes the idea that every item of the physical world has at bottom — a very deep bottom, in most instances — an immaterial source and explanation; that which we call reality arises in the last analysis from the posing of yes-no questions and the registering of equipment-evoked responses; in short, that all things physical are information-theoretic in origin” John Weeler
Jayne’s MaxEnt (Maximum Entropy principle)#
Probability is an expression of incomplete information. Given that we have some information, how should we construct a probability distribution that reflects that knowledge, but is otherwise unbiased? The best general procedure, known as Jaynes Maximum Entropy Principle , is to choose the probabilities \(p_k\) to maximize the Shanon Measure of Information of the distribution, subject to constraints that express what we do know
Fair die example
biased die
We are given infromation that on average rolling a die yields \(\langle x \rangle = 5.5\)
Problems#
Compute entropy of gaussian distribution. Plot entropy as a function of variance
Using MaxEnt approach find probability distribution with mean and variance equal to \(\mu\) and \(\sigma^2\) respectively.
Simulate 1D random walk and compute entropy by first computing probability distribution \(p_N(n)\)